Memory 深入:历史、工作记忆和语义召回
问题场景
「记住上下文」不是一个单一能力。学习助手至少有三类记忆:
- 当前对话最近说了什么。
- 用户长期偏好和学习目标。
- 很久以前提过的相似问题。
如果只保留最近 20 条消息,长期偏好可能丢失;如果把所有消息都塞回上下文,成本和噪音会迅速上升。Mastra Memory 把这些需求拆成不同机制。
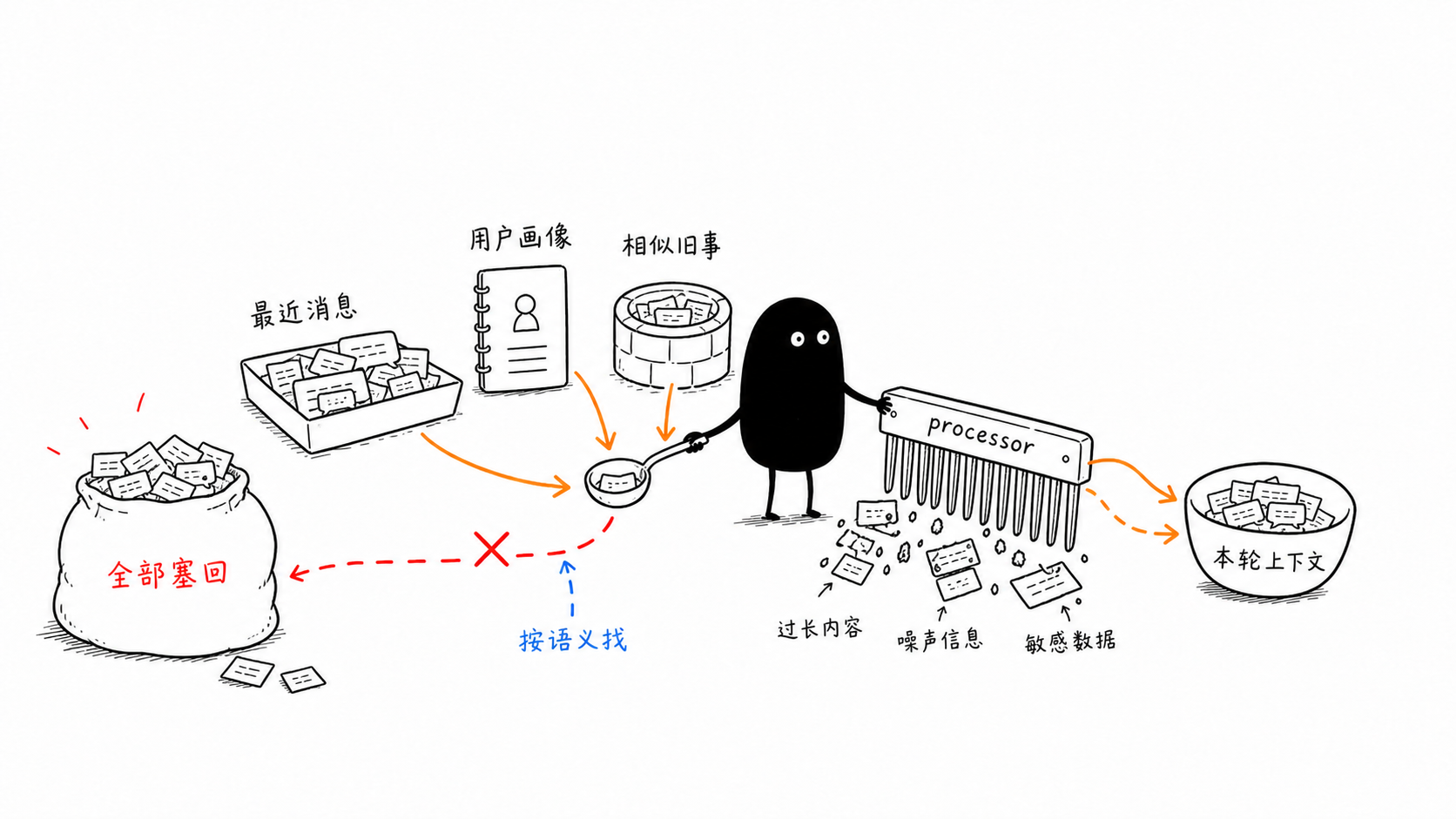
Memory 能力分层
| 能力 | 解决问题 | 适合内容 |
|---|---|---|
| Message history | 保留最近对话 | 当前线程里的问题、回答、工具结果 |
| Working memory | 保存持续有效的信息 | 用户偏好、学习目标、项目背景 |
| Semantic recall | 按语义找旧消息 | 很久以前讨论过的相似主题 |
| Memory processors | 控制进入上下文的内容 | 过滤、裁剪、优先级排序 |
| Observational memory | 长对话压缩为观察记录 | 长期运行的助手或客服 |
入门项目先用 message history;真正的学习助手可以逐步加入 working memory 和 semantic recall。
Message history:线程内连续性
Message history 依赖稳定的 resource 和 thread:
await agent.generate('我想 3 天学完 Tool', {
memory: {
resource: 'user-001',
thread: 'mastra-course',
},
})resource 是归属,thread 是会话。官方文档提醒:一个 thread 的 owner 创建后不能随意改,避免把同一个 thread ID 给不同用户复用。
Working memory:长期用户画像
官方 Working Memory 文档说明,它可以用 Markdown template,也可以用 schema。默认 scope 是 resource,表示同一用户跨线程可见。
memory: new Memory({
options: {
workingMemory: {
enabled: true,
scope: 'resource',
template: `
# Learner Profile
- Current Goal:
- Preferred Style:
- Known Topics:
- Weak Spots:
`,
},
},
})使用 schema 时,工作记忆变成可验证 JSON:
const learnerProfileSchema = z.object({
currentGoal: z.string().optional(),
preferredStyle: z.string().optional(),
knownTopics: z.array(z.string()).optional(),
weakSpots: z.array(z.string()).optional(),
})| 方式 | 优点 | 风险 |
|---|---|---|
| Markdown template | 易读,适合提示词上下文 | 程序难直接读取字段 |
| schema | 类型清楚,可供 UI/API 使用 | 需要设计字段和更新规则 |
Semantic recall:长历史语义检索
Semantic recall 本质上是对历史消息做 RAG。官方文档说明,启用后新消息会写入 vector DB,后续请求可以按语义找回相似历史。
memory: new Memory({
storage: new LibSQLStore({ id: 'memory', url: 'file:./local.db' }),
vector: new LibSQLVector({ id: 'vector', url: 'file:./local.db' }),
embedder: new ModelRouterEmbeddingModel('openai/text-embedding-3-small'),
options: {
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource',
},
},
})topK 决定找几条相似消息,messageRange 决定命中消息前后带多少上下文,scope 决定只查当前 thread 还是整个 resource。
Memory processors:防止上下文膨胀
Memory processors 用于筛选、裁剪或优先保留上下文。它们适合处理:
- 只保留最近 N 条重要消息。
- 去掉大附件或长代码块。
- 对敏感信息做过滤。
- 在上下文窗口有限时保留更相关的内容。
这和 Agent input processors 不冲突。Memory processors 关注「从存储取出的记忆如何进入上下文」,Agent processors 关注「用户输入和模型输出如何被处理」。
Study Agent 的推荐升级路线
| 阶段 | 增加能力 | 验证 |
|---|---|---|
| 当前版 | lastMessages: 20 | 同一 thread 追问 |
| 第 1 次升级 | working memory template | 记住学习风格和目标 |
| 第 2 次升级 | schema-based working memory | UI 能读取学习进度 |
| 第 3 次升级 | semantic recall | 跨 thread 找回相关学习经历 |
| 第 4 次升级 | memory processors | 长对话不爆上下文 |
Vibe coding 提示词
请为 Study Agent 设计 Memory 升级方案。
要求:
- 区分 message history、working memory、semantic recall。
- 给出 resource/thread 命名规则。
- working memory 先用 Markdown template,再说明何时换 schema。
- 不要把敏感信息写入长期记忆。
- 给出 5 条验证对话。
先输出设计表,不要直接改代码。验证方式
| 测试 | 期望 |
|---|---|
| 同一 resource + thread 追问 | 能延续上一轮 |
| 同一 resource + 不同 thread | 能读取 resource-scoped working memory |
| 不同 resource | 不能读取别人的偏好 |
| 很久前的问题 | semantic recall 能找回相关历史 |
| 用户要求删除偏好 | working memory 更新或清空 |
常见错误
| 错误 | 后果 | 修复 |
|---|---|---|
| 把所有长期信息放 message history | 上下文越来越长 | 长期偏好放 working memory |
| working memory template 太长 | 模型更新不稳定 | 模板只保留关键字段 |
| scope 选错 | 跨线程读不到或串话 | 用户画像用 resource,任务状态用 thread |
| semantic recall 不配 vector/embedder | 无法按语义找回 | 配置 vector store 和 embedding model |
小练习
为 Study Agent 写一个 Learner Profile working memory 模板。字段只保留 5 个:当前目标、学习风格、已掌握主题、薄弱点、下一步行动。然后写 3 轮对话,验证模板是否会被正确更新。