Workflow 控制流:把复杂流程拆成可验证步骤
问题场景
入门版 Workflow 只用 .then() 串联步骤。但真实任务经常需要:
- 同时检索多个资料源。
- 根据难度选择不同计划。
- 对数组里的每个条目生成练习。
- 在失败时重试或输出明确错误。
- 暂停等待人工确认。
- 在运行中向 UI 推送步骤状态。
这些不应该靠 Agent 自己「想办法」。Workflow 的价值是把流程结构写进代码。
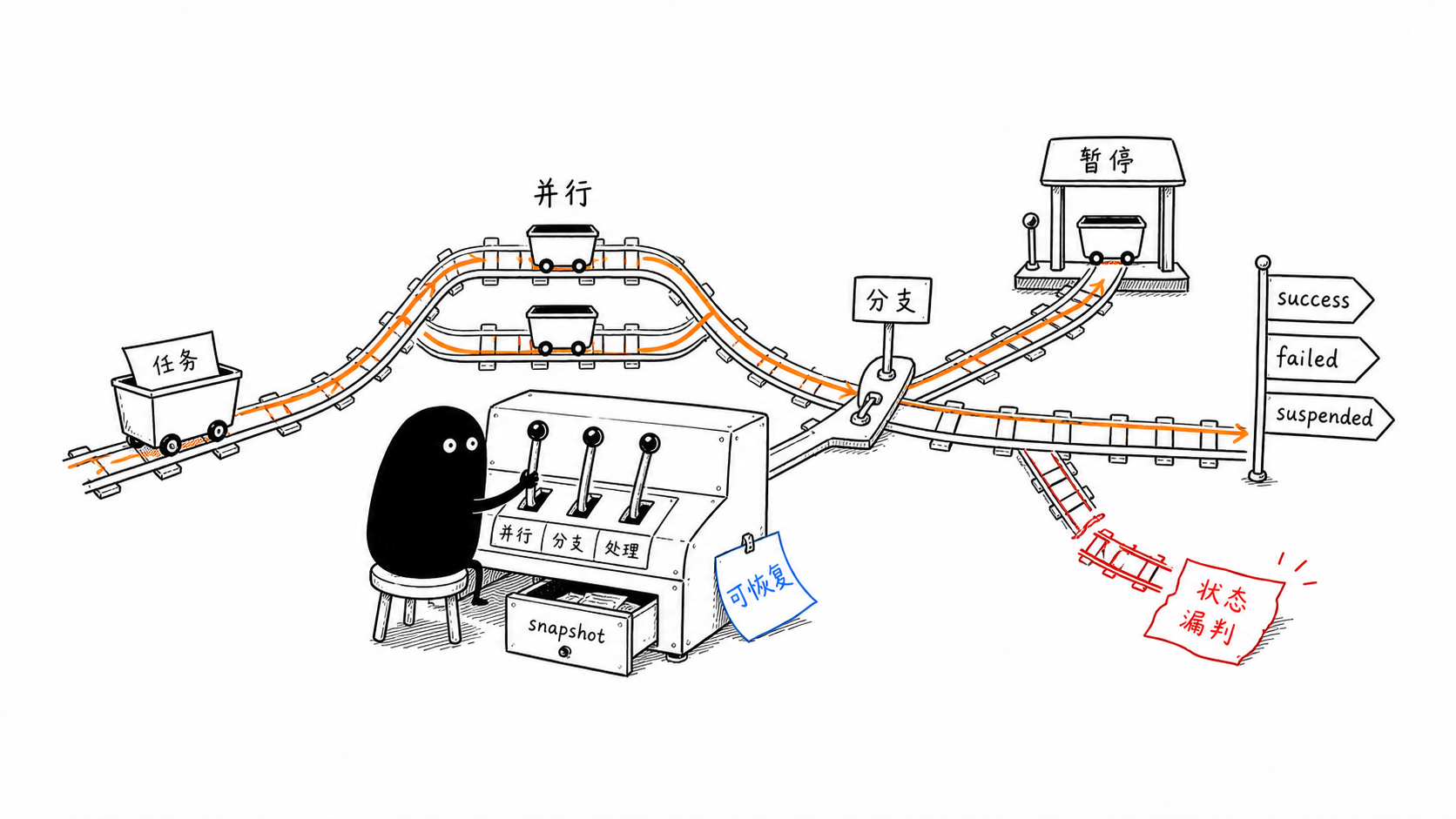
控制流总览
Mastra 官方 Workflow 控制流文档强调:每个 step 通过 schema 连接,前后步骤输入输出必须匹配;如果不匹配,就需要做输入映射。
| 控制流 | 用途 | schema 注意点 |
|---|---|---|
.then() | 顺序执行 | 上一步输出匹配下一步输入 |
.parallel() | 同时执行多个独立步骤 | 下游输入按 step id 读取 |
.branch() | 条件分支 | 分支步骤要有兼容输出 |
.foreach() | 对数组逐项处理 | 控制并发和输出集合 |
stateSchema | 跨步骤共享状态 | 不要替代正常输入输出 |
suspend() / resume() | 等待人工或外部事件 | 定义 suspendSchema 和 resumeSchema |
| snapshot | 保存暂停点 | 需要 storage,才能跨重启恢复 |
.then():默认选择
Study Agent 的学习计划工作流采用 .then(),因为目标解析、资料检索、计划生成有固定顺序:
flowchart LR
A[normalize-goal] --> B[retrieve-materials]
B --> C[build-plan]只要任务天然是「A 完成后才能做 B」,就先用 .then()。不要为了显得复杂而引入分支。
.parallel():同时做不互相依赖的事
如果学习助手未来同时搜索「官方文档」「本地笔记」「GitHub issue」,这些步骤互不依赖,可以并行:
export const researchWorkflow = createWorkflow({
id: 'research-workflow',
inputSchema: z.object({ query: z.string() }),
outputSchema: z.object({ summary: z.string() }),
})
.parallel([searchDocsStep, searchNotesStep, searchGithubStep])
.then(mergeResultsStep)
.commit()并行后的下游 step 不能直接假设只有一个输入。它会收到以 step id 为 key 的对象,合并步骤需要明确读取每个分支输出。
.branch():流程决策写进代码
例如课程难度不同,计划生成方式不同:
flowchart TD
A[estimate-level] --> B{level}
B -- beginner --> C[build-basic-plan]
B -- advanced --> D[build-project-plan]
C --> E[normalize-output]
D --> E官方文档要求分支的 schema 保持一致或由下游步骤兼容处理。否则后续步骤不知道该读哪个字段。
Workflow state:共享状态,不是万能变量
Workflow state 适合记录整个 run 的共享信息,例如:
- 已处理的资料 ID。
- 当前累计 token 或成本。
- 审批人和审批时间。
- 多个步骤都要读取的配置。
但普通业务数据仍应通过 step 输入输出传递。因为输入输出是流程契约,state 更像运行上下文。
官方 Workflow state 文档强调:step input/output 是步骤之间顺序传递的数据;state 是整个 workflow run 可读写的共享存储,并会跨 suspend/resume 周期保留。
设计判断:
| 数据 | 放哪里 |
|---|---|
| 下一步必须消费的业务对象 | step output |
| 多个 step 都需要的配置 | state |
| 审批人、审批时间、重试次数 | state |
| UI 要展示的最终结果 | workflow output |
Snapshots:暂停和恢复的依据
官方 Snapshots 文档说明,workflow 暂停时,Mastra 会保存可序列化的执行状态,包括各 step 状态、已完成 step 输出、执行路径、暂停信息和剩余重试次数。之后调用 resume() 时,workflow 会从 snapshot 恢复。
这带来一个工程要求:只要使用 suspend()、human-in-the-loop、长时间等待外部事件,就必须配置 storage。否则本地进程一重启,暂停点就无法可靠恢复。
sequenceDiagram
participant Step as Workflow Step
participant Store as Storage
participant User as Human / External Event
Step->>Store: 写入 snapshot
Step-->>User: 返回 suspended
User->>Step: resume(resumeData)
Step->>Store: 读取 snapshot
Step-->>Step: 从暂停点继续Study Agent 当前没有默认实现暂停恢复,因为主线流程不需要人工输入。但一旦扩展为「发布学习计划」「写入日历」「发送邮件」,就应该把审批点放进 Workflow 或 Tool approval,并确认 storage 已配置。
错误处理
Mastra Workflow 运行结果有状态:success、failed、suspended、tripwire。真实应用不要只假设成功:
const run = await studyPlanWorkflow.createRun()
const result = await run.start({ inputData: { goal, days } })
switch (result.status) {
case 'success':
return result.result
case 'failed':
throw result.error
case 'suspended':
return { needsHumanInput: true, suspended: result.suspended }
default:
return { status: result.status }
}调试时优先看 result.steps,它能定位哪个 step 失败。
Vibe coding 提示词
请帮我扩展 studyPlanWorkflow 的控制流设计。
需求:
- 同时搜索 courseMaterials 和 notesMaterials。
- 如果 days <= 3,生成速成计划。
- 如果 days > 3,生成项目制计划。
- 每个 step 都必须有 inputSchema 和 outputSchema。
- 并行后的 merge step 要显式读取各 step id。
- 运行结果要处理 success、failed、suspended。
先给流程图和 schema 设计,再写代码。验证方式
| 输入 | 期望 |
|---|---|
{ goal: 'Agent Tool', days: 3 } | 进入速成分支 |
{ goal: '完整项目', days: 7 } | 进入项目制分支 |
| 空资料命中 | 返回清楚的空状态,不编造 |
| 某个检索 step 抛错 | result.status === 'failed',能定位失败 step |
| 人工确认暂停 | result.status === 'suspended' |
| 暂停后恢复 | storage 中有 snapshot,resume() 能从原 step 继续 |
常见错误
| 错误 | 表现 | 修复 |
|---|---|---|
并行后直接读 inputData.hits | 字段不存在 | 按 step id 读取 |
| 分支输出结构不同 | 下游 step 类型混乱 | 统一分支输出或加 normalize step |
| 把所有数据塞进 state | 流程契约不可见 | 普通数据走 input/output |
不处理 failed 和 suspended | UI 卡住或误报成功 | 根据 result status 分支处理 |
使用 suspend() 却没有 storage | 重启后无法恢复 | 配置 LibSQLStore 或生产存储 |
| snapshot 里放不可序列化对象 | 恢复失败 | 只保存 JSON 可序列化数据 |
小练习
把 Demo 04 的工作流设计改成「并行搜索课程资料和常见错误」,再把两路结果合并为 3 天计划。先画 Mermaid 图,再让 AI 实现。