模型与路由:不要把「换模型」当成搜索替换
问题场景
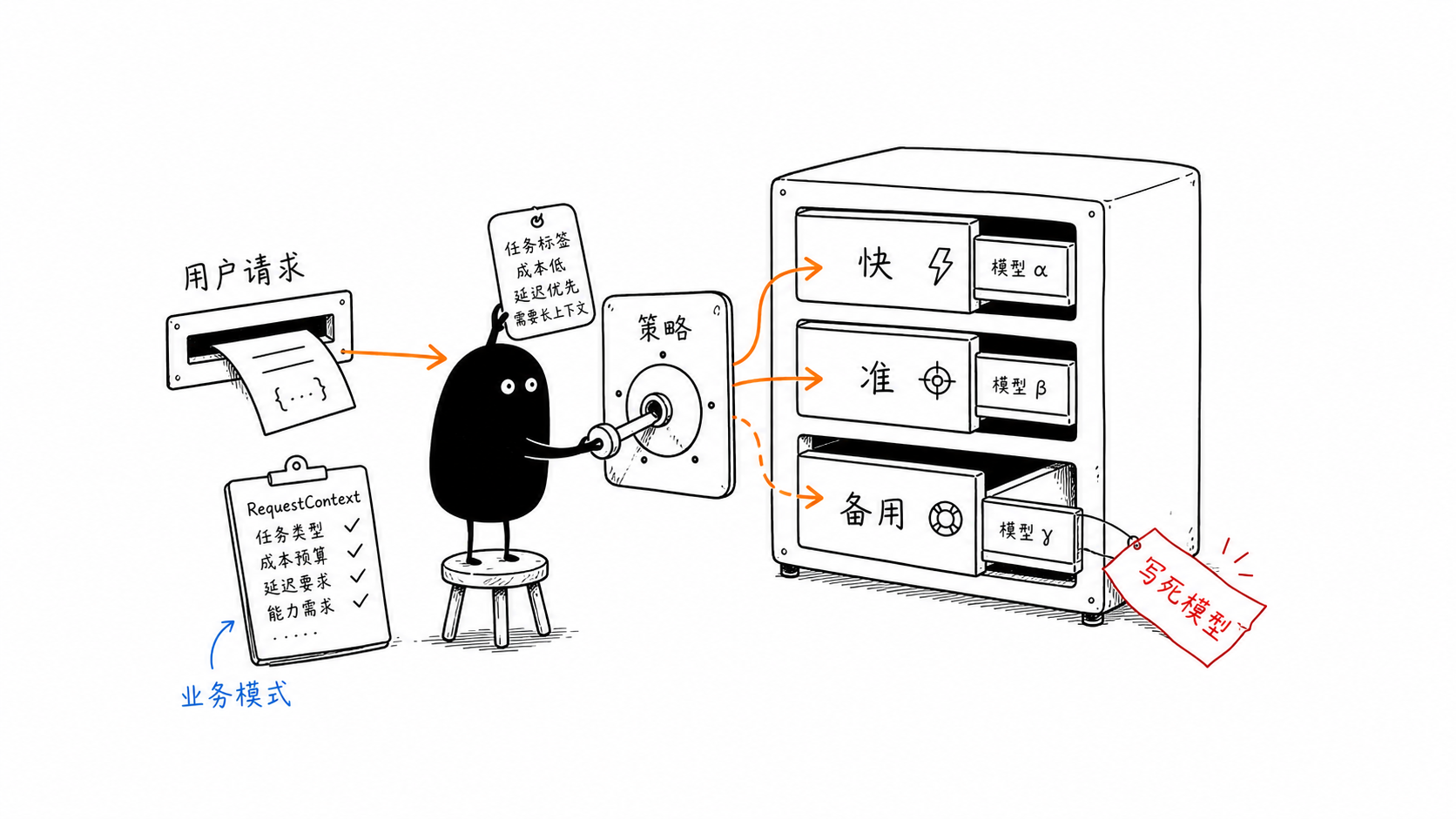
Agent 应用不是只选一个最强模型就结束。真实项目里,模型选择会同时受到任务类型、成本、延迟、上下文长度、工具调用能力、结构化输出能力和供应商稳定性的影响。
对 vibe coding 开发者来说,最常见的风险是让 AI 把模型名写死在多个文件里。这样做短期能跑,后续切换供应商、做 A/B 测试或接本地模型时会很难维护。
Mastra 的模型接口
Mastra 官方 Models 文档说明,模型可以用统一的 provider/model 字符串表示。例如:
const studyAgent = new Agent({
id: 'study-agent',
name: 'Study Agent',
instructions: '基于课程资料回答学习问题。',
model: 'openai/gpt-5.5',
})同一个 Agent 可以切到其他供应商,不需要改 Agent 的主体结构:
const studyAgent = new Agent({
id: 'study-agent',
name: 'Study Agent',
instructions: '基于课程资料回答学习问题。',
model: 'anthropic/claude-sonnet-4-6',
})官方文档还说明,Mastra 会根据模型供应商读取对应环境变量。缺少 API Key 时,应把它视为运行时配置错误,而不是把密钥写进代码。
不要把密钥交给 AI
.env 只放在本机或部署环境中。给 AI 编程工具的上下文里只需要变量名,例如 OPENAI_API_KEY、ANTHROPIC_API_KEY,不要粘贴真实值。
模型策略不是一个字段
模型策略至少要回答四个问题:
| 问题 | 设计选项 | 验证方式 |
|---|---|---|
| 哪个任务用哪个模型 | 计划生成用便宜模型,复杂推理用强模型 | 固定样例对比质量和耗时 |
| 失败时怎么办 | 设置 fallback 模型 | 模拟主模型不可用 |
| 用户能不能选模型 | 用 RequestContext 动态选择 | 两组上下文返回不同模型 |
| 本地模型能不能接入 | 使用 OpenAI-compatible endpoint | 本地服务断开时有清楚错误 |
flowchart LR
A["用户请求"] --> B["RequestContext"]
B --> C{"任务类型"}
C -- "检索摘要" --> D["低成本模型"]
C -- "复杂规划" --> E["强推理模型"]
C -- "主模型失败" --> F["fallback 模型"]
D --> G["Agent / Tool / Workflow"]
E --> G
F --> G动态模型选择
新版官方文档把请求级变量称为 RequestContext。模型字段可以写成函数,根据请求级变量决定使用哪个模型:
import { RequestContext } from '@mastra/core/request-context'
type StudyRequestContext = {
'model-tier': 'fast' | 'reasoning'
}
const context = new RequestContext<StudyRequestContext>()
context.set('model-tier', 'reasoning')
const studyAgent = new Agent({
id: 'study-agent',
name: 'Study Agent',
instructions: '基于课程资料回答学习问题。',
model: ({ requestContext }) => {
const tier = requestContext.get('model-tier')
return tier === 'reasoning' ? 'openai/gpt-5.5' : 'openai/gpt-5-mini'
},
})
await studyAgent.generate('制定 3 天学习计划', {
requestContext: context,
})这类逻辑适合放在服务端。前端最多传入「快 / 准 / 省」这类业务选项,不应该直接让未受信任用户提交任意模型 ID。
Fallback 不是质量提升器
Mastra 支持模型 fallback:主模型遇到 500、限流或超时时,自动尝试下一个模型。
const resilientAgent = new Agent({
id: 'resilient-study-agent',
name: 'Resilient Study Agent',
instructions: '基于课程资料回答学习问题。',
model: [
{ model: 'openai/gpt-5.5', maxRetries: 2 },
{ model: 'anthropic/claude-sonnet-4-6', maxRetries: 1 },
{ model: 'google/gemini-2.5-pro', maxRetries: 1 },
],
})Fallback 只解决可用性问题,不保证答案更好。不同模型的工具调用、结构化输出、长上下文表现可能不同,所以必须配合固定评估样例。
Embedding 模型也要纳入策略
RAG 和 semantic recall 会用 embedding 模型。官方 Embedding models 文档说明,embedding 也可以使用 provider/model 形式,并要关注向量维度。
import { ModelRouterEmbeddingModel } from '@mastra/core/llm'
const embedder = new ModelRouterEmbeddingModel('openai/text-embedding-3-small')设计 RAG 时要把「生成模型」和「embedding 模型」分开记录:
| 模型 | 负责内容 | 常见失败 |
|---|---|---|
| 生成模型 | 读上下文并回答 | 幻觉、工具调用不稳定、格式错误 |
| embedding 模型 | 把文本转成向量 | 维度不匹配、语义召回差 |
| rerank 模型 | 重排候选片段 | 成本上升、延迟增加 |
给 AI 编程工具的提示词
请为这个 Mastra Study Agent 设计模型策略。
要求:
- 不要把模型名散落在多个文件。
- 默认模型从环境变量 MASTRA_MODEL 读取,缺省值写在一个地方。
- 用 RequestContext 支持 fast / reasoning 两种模式。
- 设计 fallback,但说明 fallback 只处理可用性,不代表质量更高。
- 列出需要新增或读取的环境变量名,不要要求我提供真实密钥。
- 给出 5 条验证样例,比较输出质量、延迟、工具调用和结构化输出。验证清单
| 验证项 | 方法 |
|---|---|
| 模型配置集中 | 搜索 model:,确认没有无意义重复 |
| API Key 不进代码 | 搜索 sk-、api_key=、真实供应商密钥格式 |
| 动态模型生效 | 用两组 RequestContext 调用同一输入 |
| fallback 可观测 | 记录最终使用的模型和失败原因 |
| RAG 维度匹配 | embedding 模型维度与向量库 index 一致 |
| 质量可比较 | 同一 eval cases 下比较不同模型分数 |
常见错误
| 错误 | 后果 | 修复 |
|---|---|---|
| 直接让前端传模型 ID | 用户可能选择未授权模型或高成本模型 | 前端传模式,服务端映射模型 |
| 只测试最终文本 | 看不出工具调用能力差异 | 同时检查 tool-call、tool-result 和结构化输出 |
| fallback 模型能力不一致 | 主模型失败后输出格式变了 | 只选择能力相近的 fallback |
| embedding 模型随意替换 | 向量库旧数据不可用或召回变差 | 记录模型和维度,必要时重建索引 |
小练习
为 Study Agent 设计一张模型矩阵:fast、balanced、reasoning 三种模式分别使用什么生成模型、embedding 模型、RAG topK 和最大工具调用步数。再写出两条必须人工验收的评估样例。